Systems Architecture from First Principles
Deep-dive articles on distributed systems design, enterprise patterns, and architectural trade-offs — written for engineers who need to understand the why, not just the what.

The System Design Interview Framework That Senior Engineers Actually Use
Most system design interview frameworks are a checklist of buzzwords. This is not that. This post gives you the structured methodology senior engineers use in real architectural conversations: requirements scoping that eliminates ambiguity, capacity estimation from first principles, bottleneck identification with supporting math, and a trade-off articulation structure that signals architectural maturity.

Chaos Engineering: Designing Systems That Survive Failure
Chaos engineering is not about breaking things randomly — it is a discipline of controlled, hypothesis-driven experiments that reveal the gap between how your system is supposed to behave under failure and how it actually behaves. This post covers GameDay methodology, blast radius containment, and the steady-state definition patterns that make chaos experiments safe for production .NET services.

Blue-Green vs Canary Deployments: A Trade-Off Analysis for Production Systems
Every production deployment is a controlled experiment with real users as subjects. Blue-green and canary strategies differ not just in traffic splitting mechanics, but in their rollback speed, database migration constraints, and the sophistication of the feature flag synchronization they require — and choosing wrong costs you either reliability or release velocity.

Mutual TLS and Service Meshes: Zero Trust in Practice
Network perimeter security is dead — your pod-to-pod traffic is not private just because it's inside a VPC. Mutual TLS combined with a service mesh gives you cryptographic identity verification, encrypted communication, and policy enforcement between every service, without changing a line of application code.

Database Sharding Strategies: Range, Hash, and Directory-Based Approaches
Sharding is not a scalability trick — it is an architectural commitment that reshapes every query, every migration, and every operational runbook your team will ever write. This post builds the decision framework for choosing between range, hash, and directory-based sharding, with rigorous analysis of hot shard problems, cross-shard query costs, and the rebalancing mechanics that most architects underestimate.

10 Microservices Anti-Patterns That Will Ruin Your System
Microservices don't fail because of bad code — they fail because of bad boundaries. This post dissects ten structural anti-patterns that turn microservices architectures into expensive distributed monoliths, from shared databases and chatty services to synchronous dependency chains that make every deploy a coordination nightmare.

Network Latency from First Principles: What Every Architect Must Calculate
Latency is not an implementation detail — it is a physical constant that determines whether your architecture is viable. This post builds the latency budget model from the speed of light in fiber through TCP handshake mechanics, connection pool sizing, and the calculation every distributed system architect must run before committing to a topology.

Observability: Logs, Metrics, and Traces — The Three Pillars in Practice
Monitoring tells you something is wrong; observability tells you why. This post dismantles the three pillars of observability — logs, metrics, and distributed traces — and shows how OpenTelemetry, W3C traceparent propagation, and the RED and USE frameworks combine into a production-grade instrumentation strategy for .NET services.

Architecture Decision Records: The Practice That Prevents Architectural Amnesia
Every system contains decisions made by people who have long since left the building — and the reasoning left behind is almost always 'we've always done it this way.' Architecture Decision Records (ADRs) are the antidote: a lightweight, version-controlled practice that captures not just what was decided, but why, what was rejected, and what the decision costs.

Conway's Law and Team Topologies: Aligning Architecture with Organization
Your system architecture is secretly a mirror of your org chart — Conway's Law is not a metaphor, it's a structural force. This post breaks down how to wield the Inverse Conway Maneuver and Team Topologies interaction modes to design both your teams and your software intentionally.

Kubernetes for Architects: Control Planes, Scheduling, and Production Concerns
Kubernetes is not a deployment tool — it is a distributed system with its own consistency model, scheduling calculus, and failure domains. Architects who treat it as a black box make infrastructure decisions that quietly violate the guarantees they believe they have.

The C4 Model: Architecture Documentation That Engineers Actually Read
Architecture diagrams fail when they try to show everything at once, producing visuals that are simultaneously too detailed to scan and too abstract to act on. The C4 model solves this by assigning each zoom level a specific audience and a specific set of decisions it must answer.

Distributed Caching Strategies: Cache-Aside, Write-Through, and Beyond
Caching is not a performance optimization bolted onto a slow system — it is a consistency policy decision with direct implications for data correctness. The write strategy you choose determines what happens when the cache and database diverge, and in a distributed system they will diverge.

Rate Limiting Algorithms: Token Bucket, Leaky Bucket, and Sliding Windows Compared
Rate limiting is a contract between your API and its callers — one that must be enforced consistently across a distributed fleet. The algorithm you choose determines how burst traffic is absorbed, how fairness is enforced, and how expensive the enforcement is under concurrency.

The Strangler Fig Pattern: Safely Migrating Legacy Systems
The Strangler Fig pattern lets you replace a legacy system incrementally, routing traffic through a facade while the new system grows around the old one. The hard part is not the routing — it is managing data synchronization and preventing the anti-corruption layer from becoming a new source of technical debt.

SOLID Principles in the Real World: Beyond the Textbook Examples
SOLID principles are not a checklist — they are a diagnostic tool for identifying where design pressure is accumulating in your codebase before it becomes an architectural crisis. This post works through enterprise C# examples that show how each violation propagates into systemic debt.

Hexagonal Architecture: Ports, Adapters, and Why They Free Your Domain
Hexagonal Architecture is not another layering scheme — it is a dependency inversion strategy that places the domain at the center and treats all external systems as interchangeable adapters. The payoff is a domain model you can test at full fidelity without standing up a database, message broker, or HTTP server.

Message Queues vs Event Streams: Picking the Right Messaging Backbone
RabbitMQ and Kafka look similar from the outside — both accept messages and deliver them to consumers — but their architectural contracts are fundamentally different. Choosing the wrong one locks you into a messaging model that fights your workload rather than enabling it.

Eventual Consistency: What It Actually Means and How to Design for It
Eventual consistency is not a bug tolerance policy — it is a precisely defined convergence contract with identifiable failure modes. This post dismantles the CAP theorem misreadings and shows you how to build systems that stay correct when replicas diverge.

Zero-Downtime Deployments: Engineering Strategies That Actually Work
Zero-downtime deployments are not a single technique — they are a discipline that spans routing, database migration, and contract compatibility. This post dissects the mechanics of blue-green, canary, and rolling strategies so you can choose the right tool for each deployment context.

Bounded Contexts Are a Team Problem, Not a Code Problem
Bounded contexts are the most important concept in Domain-Driven Design, and the least understood. The code is the easy part — the hard part is the organisational alignment, the Conway's Law negotiation, and the context mapping decisions that determine whether your service boundaries will age well or become a maintenance liability.

Database Indexing Internals Every Architect Must Know
Indexes are the difference between sub-millisecond database queries and database-induced outages. Understanding the internal structure of B-Trees, LSM-Trees, covering indexes, and write amplification is essential.
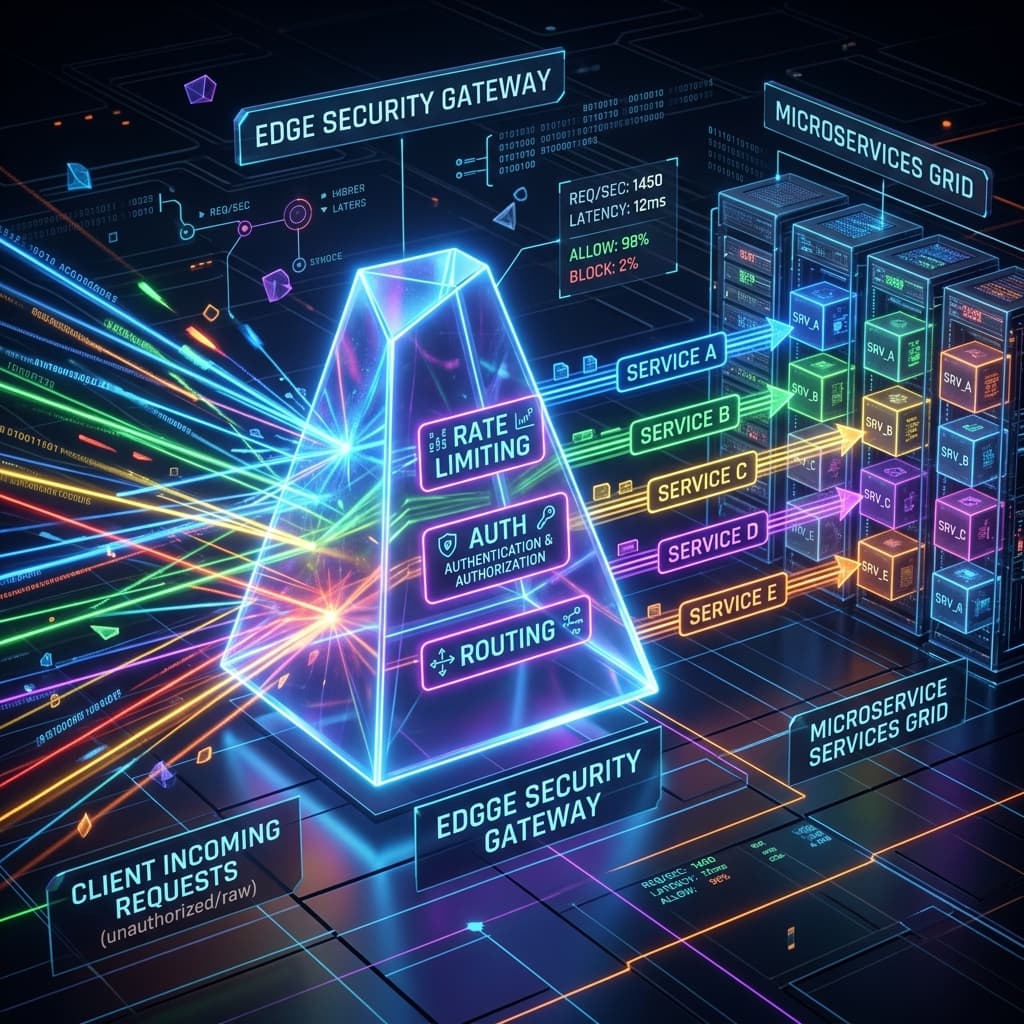
API Gateway vs Reverse Proxy vs Load Balancer: Choosing the Right Edge Layer
Edge infrastructure is the entry point to your system. Understanding the functional and physical boundary between L4 load balancers, L7 reverse proxies, and API gateways is critical for scalability, security, and operations.
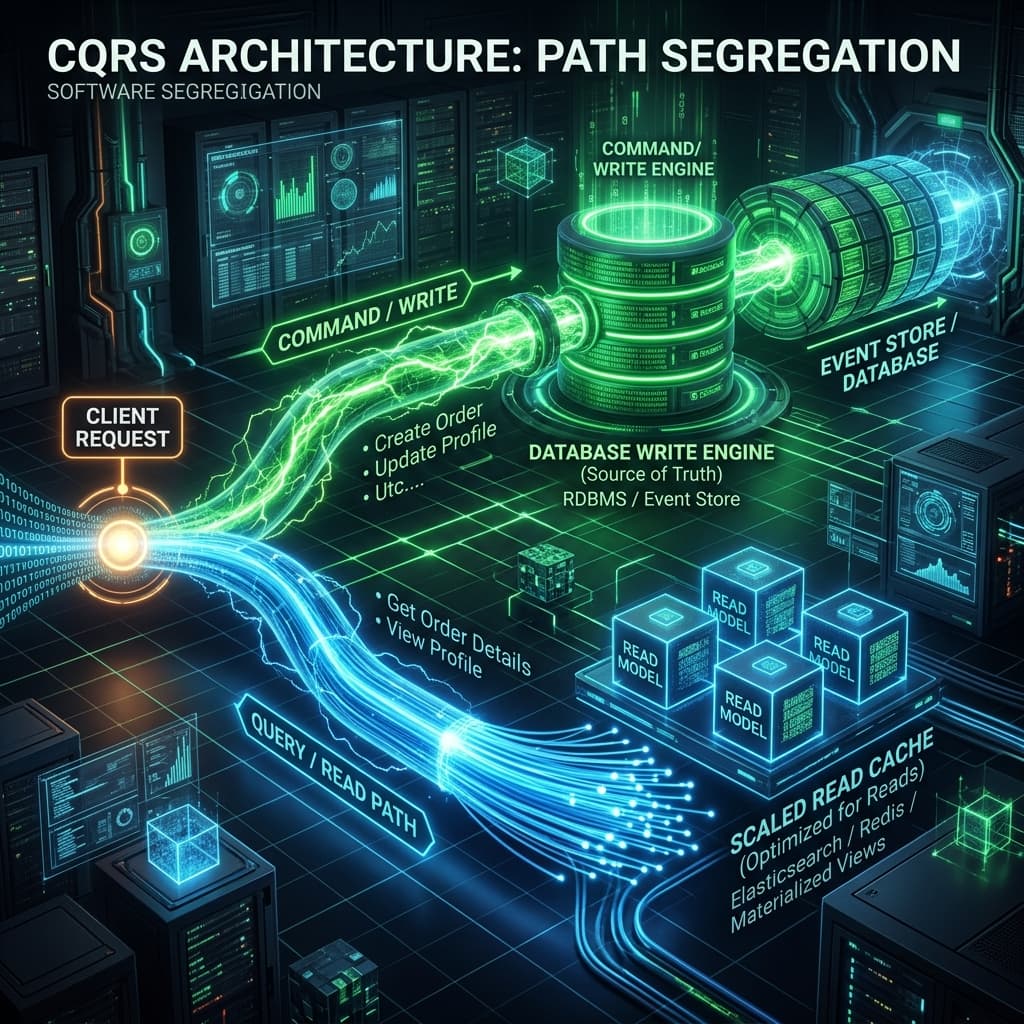
CQRS Done Right: Separating Commands from Queries at Scale
Command Query Responsibility Segregation is not simply about separate classes for reads and writes — at scale, it requires explicitly designed read models, carefully bounded eventual consistency windows, and a projection rebuild strategy that does not require a 4am maintenance window.

Implementing Circuit Breakers in .NET: Beyond the Basics
A circuit breaker is not just a retry wrapper with a threshold — it is a state machine that models the health of a dependency and actively prevents cascade failures in distributed systems. Most .NET implementations stop at the Polly defaults; this post takes you through the state transitions, probe logic, and observability patterns that production deployments require.

Designing for Idempotency: The Pattern Every Distributed System Needs
In distributed systems, every operation that crosses a network boundary must be safe to retry — not because engineers are careless, but because at-least-once delivery is the only delivery guarantee most messaging systems provide. Idempotency is not a feature you add later; it is a fundamental design constraint.

The 8 Fallacies of Distributed Computing — Still Relevant in 2024
Peter Deutsch and James Gosling's eight fallacies of distributed computing were articulated in the 1990s, but every one of them has a precise 2024 cloud-native manifestation. This post traces each fallacy from first principles to the production failure modes it produces, with mitigation patterns in C# and .NET.

Managing Distributed Transactions with the Saga Pattern
Distributed transactions spanning multiple services cannot use two-phase commit without sacrificing availability. The Saga pattern replaces atomic commits with a sequence of local transactions and compensating actions — but its isolation guarantees, or lack thereof, are what architects consistently underestimate.

Event Sourcing: Knowing When NOT To Use It
Event sourcing is one of the most over-applied patterns in modern distributed systems design. Understanding its hidden complexity costs — projection rebuild time, temporal coupling, and snapshot strategy overhead — is the difference between a maintainable architecture and an operational nightmare.

The CAP Theorem in Production: What Nobody Tells You
CAP Theorem is taught as a trilemma, but production systems expose a far messier truth: the choice is never static, and the theorem's binary framing actively misleads system design. Here's what the textbooks omit.
Ready to go deeper?
These articles are the theory. The MPC dashboard puts it into practice — interactive architecture canvas, AI mentor, and a credentialing path recognized by engineering hiring panels.
Open the Dashboard →