Cascading Failures: Modeling and Preventing Systemic Collapse
Concept
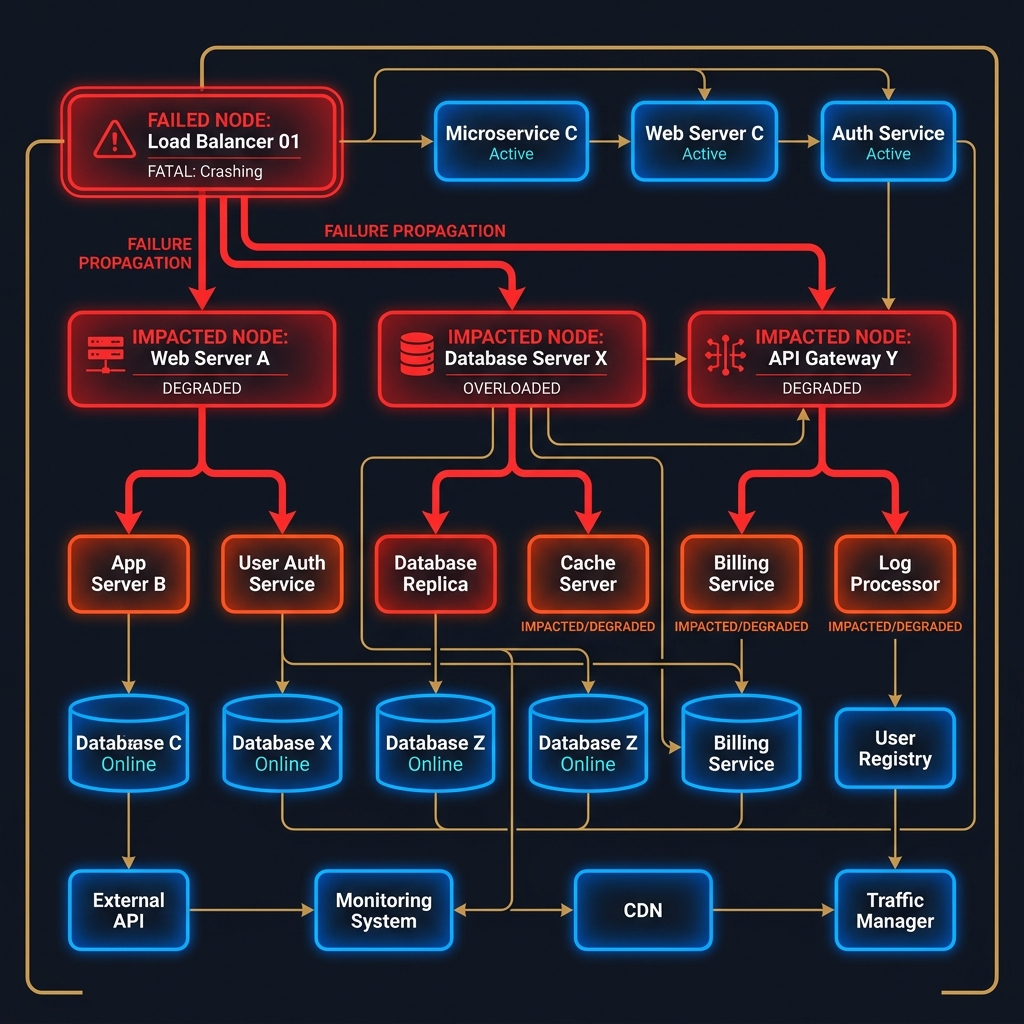
In distributed systems, a cascading failure is a positive feedback loop where a localized failure in a single component increases the probability of failure in other components. What begins as a minor anomaly—a transient network spike, a slow database query, or a single misconfigured container—can propagate across service boundaries, culminating in a total systemic collapse. Unlike independent failures, cascading failures are systemic: they exploit the implicit coupling, resource limits, and error-handling strategies of modern microservice architectures.
The propagation of a cascading failure typically follows a structured sequence:
- Primary Failure: A localized resource bottleneck, dependency outage, or misconfiguration occurs.
- Resource Exhaustion: The failing component slows down or errors out, forcing upstream clients to hold connections, threads, or memory buffers open longer.
- Queue Build-up: As threads or sockets are held, queue depths at upstream layers increase exponentially.
- Saturation and Collapse: The upstream service exhausts its own resources (e.g., thread pool starvation or Out Of Memory crashes) and fails, repeating the cycle further upstream.
Propagation Vectors
There are three primary vectors through which failures cascade in distributed environments:
1. Thread Pool and Connection Starvation
Most application servers use a thread-per-request model (such as ASP.NET Core's default Kestrel execution engine or Java servlet containers). When a downstream dependency degrades, requests block waiting for a response. If upstream services lack strict timeouts, these threads remain allocated. As new requests arrive, the thread pool is depleted. Once the thread pool is exhausted, the service can no longer accept new connections or process health checks, causing load balancers to mark the healthy node as dead, which diverts traffic to remaining healthy nodes—instantly overloading them.
2. Retry Storms (The Thundering Herd)
When a call fails, a naive client immediately retries. If thousands of clients simultaneously retry requests against a degraded downstream service, they amplify the incoming load (often by a factor of 3x to 10x). This retry storm prevents the downstream service from recovering, turning a transient database lock or garbage collection pause into a permanent outage.
3. Latency Amplification and the Long Tail
In fan-out patterns (where Service A calls Services B, C, and D in parallel), the total response time of Service A is bound by the slowest dependency (the P99 tail latency). If Service C experiences latency degradation, the entire fan-out pipeline slows down, propagating latency and resource pinning upstream.
Constraints
Designing systems resilient to cascading failures requires navigating physical and architectural constraints:
1. Little’s Law and Queue Saturation
Little's Law defines the relationship between concurrency ($L$), arrival rate ($\lambda$), and latency ($W$): $$L = \lambda \times W$$ If latency ($W$) increases due to a degraded downstream dependency, and the arrival rate ($\lambda$) remains constant, the concurrency ($L$) inside the service must increase. Because system resources (thread pools, file handles, DB connection pools) are finite, the system will eventually exceed its concurrency limit, leading to dropped packets, blocked threads, and eventual crash-looping.
2. Time Budgeting and Deadline Propagation
In deep microservice call chains (e.g., Gateway → Auth → Order → Inventory → Payment), each service adds its own latency. If the Gateway has a client-facing timeout of 2 seconds, but the downstream call chain does not communicate this budget, the Order service might initiate a database query 1.8 seconds into the request. Even if the database query succeeds in 300ms, the client has already timed out and closed the connection. The database query and subsequent processing are completely wasted, consuming critical resources that contribute to downstream congestion.
3. Load Shedding and Fair Queueing
When a service is overloaded, it must decide which requests to reject. Dropping requests at random can lead to the starvation of critical operations (e.g., checkout vs. analytics). Traditional FIFO (First-In-First-Out) queues suffer from head-of-line blocking during overload, where old, timed-out requests block the processing of fresh requests that still have a budget.
Trade-offs
Mitigating cascading failures requires balancing reliability, consistency, and resource utilization:
Load Shedding vs. Degradation Quality
Shedding load (returning HTTP 503 Service Unavailable) protects the service from collapse but directly impacts the user experience. The alternative is graceful degradation: serving stale data from a cache, omitting non-critical components (like recommendations on an e-commerce page), or returning static stubs. The trade-off is architectural complexity; the core domain must be decoupled from secondary dependencies, and clients must handle partial payloads.
Static Timeouts vs. Adaptive Timeouts
Static timeouts are simple but fragile. If set too low, they cause false-positive failures during transient spikes. If set too high, they fail to protect against thread starvation. Adaptive timeouts (such as TCP-style moving average latency tracking) adjust dynamically to current network conditions but introduce non-deterministic failure modes that are difficult to debug in production.
Code
To prevent cascading failures in deep call chains, we must implement Deadline Propagation. In C#, this is achieved by propagating a CancellationToken derived from an incoming HTTP header representing the remaining request budget.
The following custom ASP.NET Core middleware extracts the deadline header, calculates the remaining lifetime, and links it to the request's HttpContext.RequestAborted token.
using System;
using System.Diagnostics;
using System.Threading;
using System.Threading.Tasks;
using Microsoft.AspNetCore.Http;
using Microsoft.Extensions.Logging;
namespace Mpc.Resilience.Middleware
{
public class DeadlinePropagationMiddleware
{
private const string DeadlineHeaderKey = "X-Request-Deadline-Utc";
private readonly RequestDelegate _next;
private readonly ILogger<DeadlinePropagationMiddleware> _logger;
public DeadlinePropagationMiddleware(RequestDelegate next, ILogger<DeadlinePropagationMiddleware> logger)
{
_next = next ?? throw new ArgumentNullException(nameof(next));
_logger = logger ?? throw new ArgumentNullException(logger);
}
public async Task InvokeAsync(HttpContext context)
{
if (context.Request.Headers.TryGetValue(DeadlineHeaderKey, out var headerValue) &&
long.TryParse(headerValue, out var deadlineTicks))
{
var deadlineUtc = new DateTime(deadlineTicks, DateTimeKind.Utc);
var remainingTime = deadlineUtc - DateTime.UtcNow;
if (remainingTime <= TimeSpan.Zero)
{
_logger.LogWarning("Request deadline has already expired. Shedding load immediately.");
context.Response.StatusCode = StatusCodes.Status503ServiceUnavailable;
await context.Response.WriteAsync("Request deadline expired before processing.");
return;
}
// Create a CTS that fires when either the remaining budget expires OR the client disconnects
using var budgetCts = new CancellationTokenSource(remainingTime);
using var linkedCts = CancellationTokenSource.CreateLinkedTokenSource(
context.RequestAborted,
budgetCts.Token);
// Override the RequestAborted token with our linked deadline token
context.RequestAborted = linkedCts.Token;
try
{
await _next(context);
}
catch (OperationCanceledException) when (budgetCts.IsCancellationRequested)
{
_logger.LogWarning("Request execution cancelled: Deadline exceeded.");
context.Response.StatusCode = StatusCodes.Status504GatewayTimeout;
await context.Response.WriteAsync("Request execution deadline exceeded.");
}
}
else
{
// Fallback: If no deadline header, proceed with default request lifetime
await _next(context);
}
}
}
}
The matching HttpClient handler propagates this deadline to downstream services, ensuring that the time budget shrinks proportionally as the request travels down the stack:
using System;
using System.Net.Http;
using System.Threading;
using System.Threading.Tasks;
namespace Mpc.Resilience.Http
{
public class DeadlinePropagationHandler : DelegatingHandler
{
private const string DeadlineHeaderKey = "X-Request-Deadline-Utc";
protected override async Task<HttpResponseMessage> SendAsync(
HttpRequestMessage request,
CancellationToken cancellationToken)
{
// If the current execution context already has a deadline, propagate it.
// Otherwise, establish a deadline based on a local default timeout.
if (!request.Headers.Contains(DeadlineHeaderKey))
{
var deadlineUtc = DateTime.UtcNow.AddSeconds(5); // Default 5s budget
request.Headers.Add(DeadlineHeaderKey, deadlineUtc.Ticks.ToString());
}
// Monitor client-side cancellation and abort early
cancellationToken.ThrowIfCancellationRequested();
try
{
return await base.SendAsync(request, cancellationToken);
}
catch (OperationCanceledException)
{
// Custom diagnostic logging or telemetry tracking can be placed here
throw;
}
}
}
}
Flow of Failure Cascades and Mitigations
The diagram below illustrates the propagation vectors of a cascading failure and where defensive boundaries must be inserted to disrupt the feedback loop:
graph TD
Client[Client Traffic] -->|1. Overload| GW[API Gateway]
GW -->|2. High Concurrency| Auth[Auth Service]
Auth -->|3. Latency / Starvation| DB[(Database)]
subgraph Defensive Boundaries
RateLimiter[Token Bucket Rate Limiter] -.->|Sheds Load| Client
DeadlineGate[Deadline Propagation Middleware] -.->|Aborts Straggler Requests| Auth
CircuitBreaker[Circuit Breaker] -.->|Fails Fast on Degradation| GW
end
style RateLimiter fill:#d4a359,stroke:#0d101a,color:#0d101a
style DeadlineGate fill:#d4a359,stroke:#0d101a,color:#0d101a
style CircuitBreaker fill:#d4a359,stroke:#0d101a,color:#0d101a
style DB fill:#0d101a,stroke:#d4a359,stroke-width:2px,color:#fff