Event Schema Evolution: Avro vs Protobuf in Distributed Streams
Concept
In distributed, event-driven architectures, events are the primary source of truth and communication. Over time, business requirements change, requiring event schemas to evolve. Adding new fields, deprecating old ones, or changing data types must be managed without disrupting downstream consumers that may run different versions of the code.
This article evaluates two dominant binary serialization frameworks—Apache Avro and Protocol Buffers (Protobuf)—and analyzes how they achieve schema evolution in conjunction with a central schema registry. This topic maps directly to the registry and message lifecycle concepts in Module 9: Event-Driven Architectures (EDA).
sequenceDiagram
autonumber
participant Producer as Producer Node
participant Registry as Confluent Schema Registry
participant Broker as Kafka Broker
participant Consumer as Consumer Node
Note over Producer, Registry: 1. Schema Registration / Verification
Producer->>Registry: Register/Retrieve Schema for "UserRegistered"
Registry-->>Producer: Return Schema ID (e.g., ID: 42)
Note over Producer, Broker: 2. Serialize Payload with Schema ID Prefix
Producer->>Producer: Serialize payload using Avro/Protobuf
Producer->>Producer: Prepend Magic Byte (0) + 4-byte Schema ID (42)
Producer->>Broker: Produce Message [Magic Byte][ID 42][Binary Payload]
Note over Consumer, Registry: 3. Schema ID Resolution
Broker->>Consumer: Consume Message
Consumer->>Consumer: Extract Schema ID (42) from prefix
Consumer->>Registry: Fetch Schema for ID 42 (if not cached)
Registry-->>Consumer: Return Writer Schema
Consumer->>Consumer: Perform Schema Resolution (Writer Schema -> Reader Schema)
Consumer->>Consumer: Deserialize Binary Payload
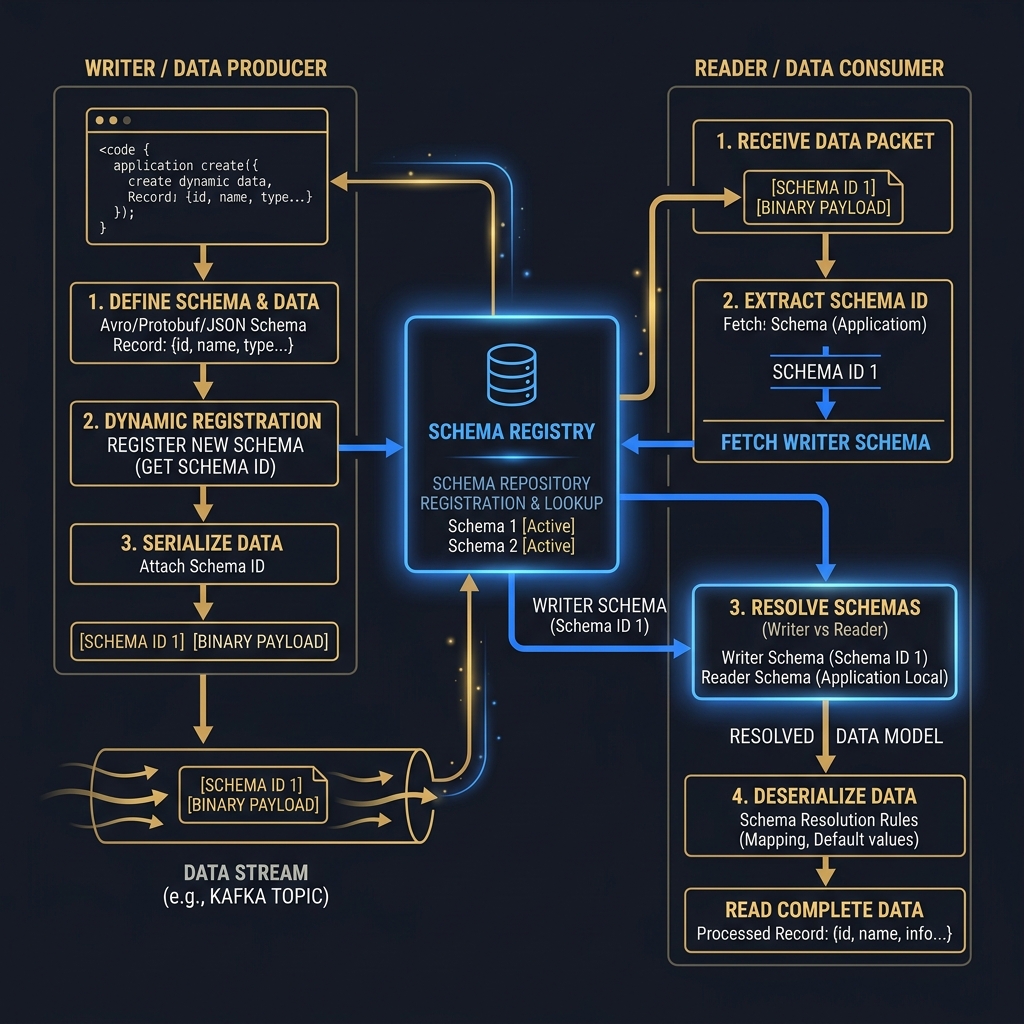
Apache Avro: Writer and Reader Schema Resolution
Avro separates the schema definition from the serialized data payload. The binary payload contains only the raw value bytes—there are no tags, field names, or type identifiers embedded within the payload.
To deserialize Avro data, a reader must possess the exact schema used to write the data (the Writer Schema) and the schema the reading application expects (the Reader Schema).
The schema resolution process is governed by the following rules:
- Field Matching: The reader matches fields by name. If the writer schema contains a field not present in the reader schema, it is ignored.
- Default Values: If the reader schema contains a field not present in the writer schema, it must have a default value defined. Otherwise, deserialization fails.
- Type Promotion: Avro supports automatic type promotion (e.g., promoting an
intto alongor afloatto adouble).
Because Avro requires the writer schema to decode data, distributed streams use a Schema Registry. The producer registers the schema before producing. The message payload is prepended with a 5-byte header: a 1-byte magic byte (always 0) and a 4-byte integer representing the schema ID. The consumer extracts this ID, fetches the writer schema from the registry (which it caches locally), and performs schema resolution against its compiled reader schema.
Protocol Buffers: Tag-Based Evolution
Unlike Avro, Protobuf encodes field identifiers directly into the serialized binary payload. Every field in a .proto file is assigned a unique integer called a Tag Number.
The serialized payload is a sequence of key-value pairs where the "key" consists of the tag number and the wire type (e.g., Varint, Length-delimited), and the "value" is the raw payload.
Protobuf Binary Payload:
[Tag Number | Wire Type] [Length (optional)] [Value]
Because of this tag-based layout, Protobuf does not strictly require a writer schema to decode a payload into its structural elements (though it does require the schema to map tag numbers back to human-readable field names).
- New Fields: If a reader receives a payload containing a new tag number not present in its proto definition, it simply skips the unknown tag. In modern Protobuf, these are preserved in an "unknown fields" buffer.
- Removed Fields: If a field is deprecated and removed, the reader simply ignores that tag number. However, the tag number must never be reused by a different field in the future, as this would cause corruption. The
reservedkeyword is used to enforce this constraint.
Constraints
When designing schemas for long-lived distributed streams, architects must operate within physical network and CPU constraints.
1. Registry Network Overhead and Cold Starts
While schema caching minimizes runtime latency, cache misses on a cold start can degrade system performance.
- If a consumer service scales out dynamically under heavy load, the new replicas must query the Schema Registry for every new schema ID they encounter. This synchronous HTTP call introduces a round-trip network hop (typically 2-15ms) which blocks the message-processing thread, causing transient consumption lag.
2. Binary Payload Size Constraints
The choice between Avro and Protobuf has a direct impact on network packet sizes.
- Avro is highly space-efficient because it does not include field tags. For small payloads (e.g., a simple event with 5 fields), the 5-byte registry prefix is the only overhead.
- Protobuf includes a tag-header byte for every field. If a schema contains a deeply nested hierarchy, the tag overhead can increase the payload size by 10-30% compared to Avro, leading to increased network throughput and storage utilization on the Kafka brokers.
3. Compatibility Rules Enforcement
Schema registries enforce compatibility rules during schema registration. A mismatch in compatibility configuration between producer and consumer codebases will break pipeline execution:
- BACKWARD Compatibility: Consumers using the new schema can read data written with the old schema. (Constraint: New fields must have defaults; removed fields must not be required).
- FORWARD Compatibility: Consumers using the old schema can read data written with the new schema. (Constraint: Removed fields must have defaults; new fields must not be required).
- FULL Compatibility: Both backward and forward compatibility are enforced.
Trade-offs
Choosing between Avro and Protobuf involves balancing coupling, performance, and programming model ergonomics.
1. Schema Coupling vs. Autonomy
- Avro (High Schema Registry Coupling): Avro requires the schema registry to function in a distributed system. You cannot decode a raw Avro byte stream without fetching the writer schema.
- Trade-off: Enforces strict governance and prevents "wild west" schema changes. However, it introduces a hard runtime dependency on the Schema Registry. If the registry is down and the cache is cold, processing fails.
- Protobuf (High Code Generation Coupling): Protobuf can serialize and deserialize without a registry by relying on generated class code.
- Trade-off: Higher autonomy and resilience to registry downtime. However, it requires distributing compiled proto classes across all teams, leading to potential code dependency synchronization bottlenecks.
2. Code-First vs. Contract-First Development
- Protobuf (Strictly Contract-First): Developers must write
.protofiles and use the Protobuf compiler (protoc) to generate target language classes.- Trade-off: Guarantees cross-language schema consistency. However, it adds compilation complexity to CI/CD pipelines.
- Avro (Flexibility): Avro supports both contract-first (defining schemas in JSON
.avscfiles) and code-first approaches (dynamically generating schemas using reflection on runtime objects).- Trade-off: Speeds up prototyping and early-stage development, but dynamic reflection-based schemas can lead to unintentional, breaking schema changes during deployments if runtime classes are refactored.
Implementation: Programmatic Schema Resolution in C#
The following C# code demonstrates how to implement a producer and consumer using Apache Avro with Confluent Schema Registry integration, demonstrating how schema resolution and caching are handled under the hood using the .NET client.
1. Contract Definition (UserRegistered.avsc)
{
"namespace": "Mpc.Events",
"type": "record",
"name": "UserRegistered",
"fields": [
{ "name": "UserId", "type": "string" },
{ "name": "Email", "type": "string" },
{ "name": "RegisteredAtUtc", "type": "long" },
{ "name": "PreferredLanguage", "type": ["null", "string"], "default": null }
]
}
2. C# Producer & Consumer Implementation
using System;
using System.IO;
using System.Threading;
using System.Threading.Tasks;
using Confluent.Kafka;
using Confluent.SchemaRegistry;
using Confluent.SchemaRegistry.Serdes;
using Microsoft.Extensions.Logging;
namespace Mpc.Serialization
{
// Programmatically generated/defined class mapping the Avro schema
public class UserRegistered
{
public string UserId { get; set; }
public string Email { get; set; }
public long RegisteredAtUtc { get; set; }
public string PreferredLanguage { get; set; }
}
public class AvroStreamingPipeline
{
private readonly string _bootstrapServers;
private readonly string _registryUrl;
private readonly ILogger _logger;
public AvroStreamingPipeline(string bootstrapServers, string registryUrl, ILogger logger)
{
_bootstrapServers = bootstrapServers;
_registryUrl = registryUrl;
_logger = logger;
}
public async Task RunProducerAsync(string topic, UserRegistered userEvent, CancellationToken cancellationToken)
{
// Configure Schema Registry client
var schemaRegistryConfig = new SchemaRegistryConfig { Url = _registryUrl };
using var schemaRegistry = new CachedSchemaRegistryClient(schemaRegistryConfig);
// Configure Kafka Producer
var producerConfig = new ProducerConfig { BootstrapServers = _bootstrapServers };
using var producer = new ProducerBuilder<string, UserRegistered>(producerConfig)
.SetValueSerializer(new AvroSerializer<UserRegistered>(schemaRegistry, new AvroSerializerConfig
{
// Automatically register the schema if it is not present in the registry
AutoRegisterSchemas = true,
// Use a 100-item cache for schema IDs
SubjectNameStrategy = SubjectNameStrategy.Topic
}))
.Build();
try
{
var message = new Message<string, UserRegistered>
{
Key = userEvent.UserId,
Value = userEvent
};
var deliveryReport = await producer.ProduceAsync(topic, message, cancellationToken);
_logger.LogInformation("Event produced to partition {Partition} at offset {Offset} with schema registration.",
deliveryReport.Partition, deliveryReport.Offset);
}
catch (ProduceException<string, UserRegistered> ex)
{
_logger.LogError(ex, "Failed to produce Avro payload due to serialization/broker error.");
}
}
public async Task StartConsumerLoopAsync(string topic, string groupId, CancellationToken cancellationToken)
{
var schemaRegistryConfig = new SchemaRegistryConfig { Url = _registryUrl };
using var schemaRegistry = new CachedSchemaRegistryClient(schemaRegistryConfig);
var consumerConfig = new ConsumerConfig
{
BootstrapServers = _bootstrapServers,
GroupId = groupId,
AutoOffsetReset = AutoOffsetReset.Earliest,
EnableAutoCommit = false
};
// Setup consumer with Schema Registry integration for Value deserialization
using var consumer = new ConsumerBuilder<string, UserRegistered>(consumerConfig)
.SetValueDeserializer(new AvroDeserializer<UserRegistered>(schemaRegistry))
.SetErrorHandler((_, error) => _logger.LogError("Consumer error: {Reason}", error.Reason))
.Build();
consumer.Subscribe(topic);
try
{
while (!cancellationToken.IsCancellationRequested)
{
var consumeResult = consumer.Consume(cancellationToken);
if (consumeResult != null)
{
var userEvent = consumeResult.Message.Value;
_logger.LogInformation("Consumed event for user {UserId}. Language preference: {Lang}",
userEvent.UserId, userEvent.PreferredLanguage ?? "Not Specified");
// Manually commit offsets to ensure at-least-once processing semantics
consumer.Commit(consumeResult);
}
}
}
catch (OperationCanceledException)
{
_logger.LogInformation("Gracefully stopping consumer loop.");
}
finally
{
consumer.Close();
}
}
}
}