Kafka Consumer Group Rebalancing: Mechanics and Mitigation
Concept
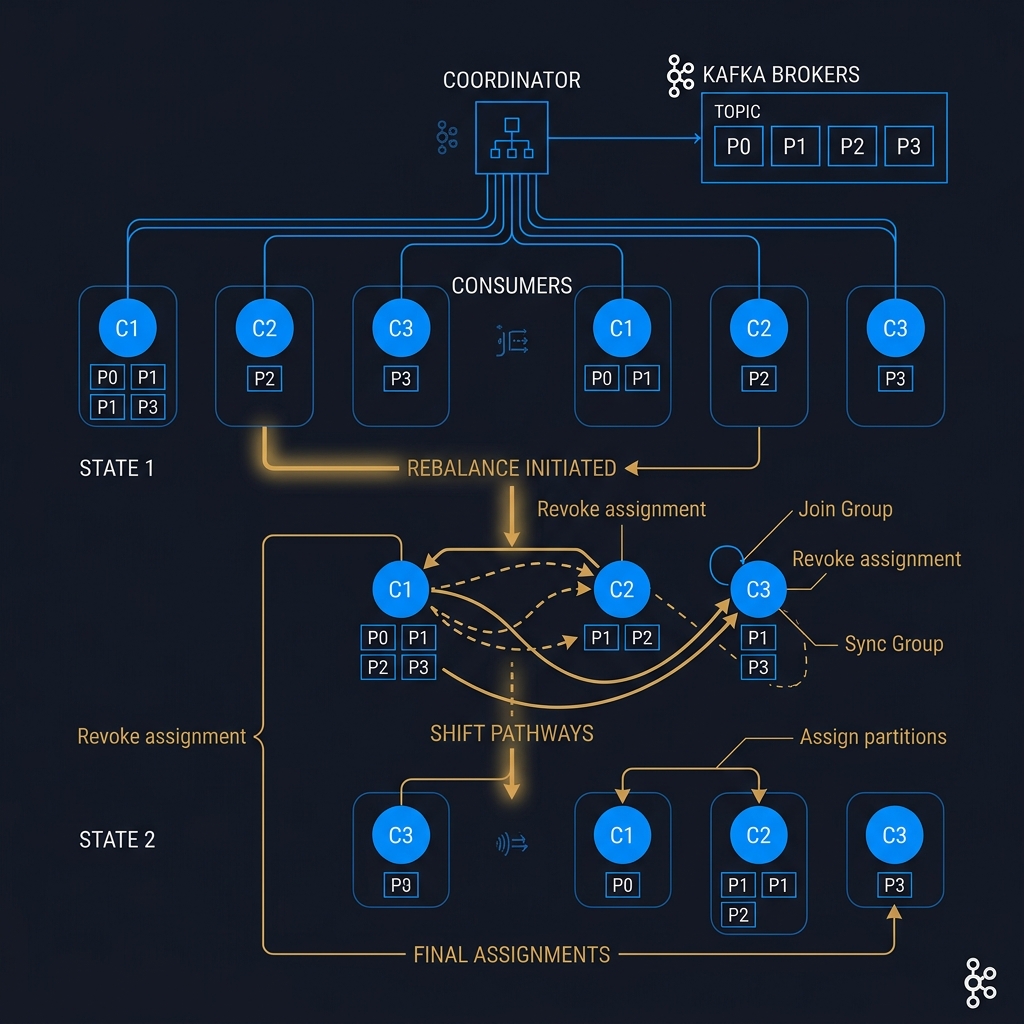
In distributed event streaming with Apache Kafka, scalability is achieved by partitioning topics. A consumer group allows a pool of cooperating processes to divide the consumption of partitions. However, this division of labor is dynamic. When consumers join or leave a group, or when topic partitions change, Kafka initiates a process known as a Consumer Group Rebalance.
Understanding consumer group rebalances requires analyzing the coordination protocol, group membership states, and partition assignment strategies from a first-principles perspective. This article maps directly to the concepts covered in Module 9: Event-Driven Architectures (EDA).
sequenceDiagram
autonumber
participant C1 as Consumer 1
participant C2 as Consumer 2 (New)
participant Coord as Group Coordinator (Broker)
participant Leader as Group Leader (Consumer 1)
Note over C1,Coord: Consumer 1 is active & heartbeating
C2->>Coord: JoinGroup Request (State: PreparingRebalance)
Coord-->>C1: Heartbeat Response contains Rebalance Trigger
C1->>Coord: JoinGroup Request
Coord-->>C1: JoinGroup Response (Elected Leader, Member List)
Coord-->>C2: JoinGroup Response (Member)
Leader->>Leader: Runs Assignment Algorithm (e.g., CooperativeSticky)
C1->>Coord: SyncGroup Request (Sends Assignments)
C2->>Coord: SyncGroup Request (Empty Payload)
Coord-->>C1: SyncGroup Response (Assigned Partitions)
Coord-->>C2: SyncGroup Response (Assigned Partitions)
The Coordination Protocol
The lifecycle of a consumer group is governed by a Group Coordinator—a specific Kafka broker selected based on the hash of the consumer group ID (specifically, hash(groupId) % __consumer_offsets).
The rebalance process follows a multi-stage protocol:
- Rebalance Trigger: The coordinator detects a change in group membership (e.g., a new consumer joins, an existing consumer misses heartbeats, or metadata changes such as partition expansion). It transitions the group status to
PreparingRebalance. - JoinGroup Stage: All active consumers must send a
JoinGrouprequest to the coordinator. The coordinator pauses message delivery and waits for all active members to respond, or until themax.poll.interval.mstimer expires. - Leader Election and Strategy Selection: The coordinator elects one of the consumers in the group as the Group Leader (typically the first to send the
JoinGrouprequest). The coordinator responds to the leader with a list of active members and the configured partition assignors. The leader runs the assignment algorithm locally. - SyncGroup Stage: The leader sends the computed partition assignments to the coordinator via a
SyncGrouprequest. Non-leader consumers send emptySyncGrouprequests. The coordinator caches these assignments and distributes them back to all consumers in the response.
Rebalance Protocols: Eager vs. Cooperative Sticky
The impact of a rebalance on system throughput is heavily influenced by the assignment protocol.
Eager Protocol (Stop-the-World): Under the eager protocol (used by default in older clients), all consumers revoke their assigned partitions before joining the
JoinGroupstage. Consequently, consumption halts entirely across the entire consumer group during the rebalance window. If a single consumer fails to join quickly, the entire system stalls, causing massive processing latency spikes.Cooperative Sticky Protocol: Introduced in Kafka 2.4, the cooperative protocol allows consumers to retain their partition assignments during the initial phase of a rebalance. The group leader computes the diff between the current assignments and the new desired state. Partitions that need to change ownership are revoked in a first phase, while unaffected partitions continue to process messages uninterrupted. A second, brief rebalance is then triggered to assign the revoked partitions to their new owners.
Constraints
Architects must navigate physical and operational constraints when tuning consumer configurations to prevent cluster degradation.
1. The Thread Coupling Boundary
In many Kafka clients (including the .NET client wrapped around librdkafka), the network operations (heartbeats) and the application processing logic (consuming and committing offsets) operate on different layers, though their timeouts are bound.
- The Heartbeat Thread: Runs in the background and sends periodic pings to the coordinator. If it fails to send a heartbeat within
session.timeout.ms, the broker assumes the consumer is dead and triggers a rebalance. - The Application Loop: Calls
Consume()orPoll()to fetch batches of records. If the processing of a batch takes longer thanmax.poll.interval.ms, the consumer voluntarily leaves the group, triggering a rebalance. This is a safety mechanism to prevent stuck partitions.
2. Commit Latency vs. Dual-Commit Hazards
During a rebalance, if a partition is revoked from a consumer, it must commit its current offset before the partition is reassigned.
- If the consumer commits offsets asynchronously to optimize performance, it may fail to ensure the coordinator registers the commit before the rebalance completes. This leads to duplicate processing (at-least-once delivery duplicates) once the new owner takes over.
- If the consumer commits synchronously, consumption latency increases due to network round-trips to the coordinator during revocation.
3. Partition Count and Metadata Payload Size
The execution time of the partition assignment algorithm scale with $O(P \times C)$, where $P$ is the partition count and $C$ is the consumer count. Having thousands of partitions per topic combined with frequent dynamic rebalances can saturate the coordinator broker’s CPU and memory, causing cascading network timeouts.
Trade-offs
Mitigating rebalance latency requires balancing developer velocity, failover time, and resource efficiency.
1. Static Membership (group.instance.id) vs. Dynamic Membership
In dynamic membership, every restart of a consumer container (e.g., during rolling deployments in Kubernetes) results in the consumer obtaining a new member ID, which triggers a full rebalance.
- Static Membership: By configuring
group.instance.id, the consumer registers with a persistent identifier. If the container restarts and reconnects within thesession.timeout.mswindow, the coordinator allows it to reclaim its existing partitions without triggering a rebalance.- Trade-off: Decreases rebalance frequency during deployment. However, it delays partition failover: if a consumer genuinely crashes and does not return, its partitions will sit idle for the entire duration of
session.timeout.msbefore the coordinator reassigns them.
- Trade-off: Decreases rebalance frequency during deployment. However, it delays partition failover: if a consumer genuinely crashes and does not return, its partitions will sit idle for the entire duration of
2. Session Timeout Duration: Aggressive vs. Conservative
- Aggressive Timeout (e.g.,
session.timeout.ms = 6000): Detects node crashes almost instantly, minimizing message processing gaps.- Trade-off: Vulnerable to transient network hiccups. A minor network packet drop or a temporary garbage collection pause on the consumer can trigger a false positive rebalance, disrupting the entire group.
- Conservative Timeout (e.g.,
session.timeout.ms = 45000): Protects against false positives due to network fluctuation or GC sweeps.- Trade-off: Leaves partitions unconsumed for up to 45 seconds if a node hard-crashes.
Implementation: Resilient C# Consumer with Cooperative Sticky Assignment
The following C# code demonstrates how to implement a resilient consumer utilizing the Cooperative Sticky Assignor, static membership, and robust handling of partition revocation events to guarantee that offsets are successfully committed before partitions shift.
using System;
using System.Collections.Generic;
using System.Threading;
using System.Threading.Tasks;
using Confluent.Kafka;
using Microsoft.Extensions.Logging;
namespace Mpc.Kafka.Consumers
{
public class ResilientKafkaConsumer<TKey, TValue>
{
private readonly ConsumerConfig _config;
private readonly string _topic;
private readonly ILogger _logger;
public ResilientKafkaConsumer(string bootstrapServers, string groupId, string instanceId, string topic, ILogger logger)
{
_topic = topic ?? throw new ArgumentNullException(nameof(topic));
_logger = logger ?? throw new ArgumentNullException(nameof(logger));
_config = new ConsumerConfig
{
BootstrapServers = bootstrapServers,
GroupId = groupId,
// Enable Static Membership to prevent rebalances on rapid rolling restarts
GroupInstanceId = instanceId,
// Configure cooperative sticky assignment to prevent stop-the-world rebalances
PartitionAssignmentStrategy = PartitionAssignmentStrategy.CooperativeSticky,
// Set session timeout to tolerate transient network issues but failover in a reasonable time
SessionTimeoutMs = 15000,
HeartbeatIntervalMs = 3000,
// Guard against slow processing loops causing false-positive rebalances
MaxPollIntervalMs = 300000, // 5 minutes
// Disable auto-commit to control offset persistence precisely during rebalance events
EnableAutoCommit = false,
AutoOffsetReset = AutoOffsetReset.Earliest
};
}
public async Task StartConsumeLoopAsync(CancellationToken cancellationToken)
{
using var consumer = new ConsumerBuilder<TKey, TValue>(_config)
.SetPartitionsAssignedHandler((c, partitions) =>
{
_logger.LogInformation("Cooperative Rebalance: Partitions assigned: {Partitions}",
string.Join(", ", partitions));
})
.SetPartitionsRevokedHandler((c, partitions) =>
{
_logger.LogWarning("Cooperative Rebalance: Partitions revoked: {Partitions}. Committing pending offsets synchronously.",
string.Join(", ", partitions));
try
{
// Commit synchronously during revocation to ensure the new partition owner
// does not reprocess duplicate messages.
c.Commit();
}
catch (KafkaException ex)
{
_logger.LogError(ex, "Failed to commit offsets during partition revocation.");
}
})
.SetErrorHandler((c, error) =>
{
_logger.LogError("Kafka internal error encountered. Code: {Code}, Reason: {Reason}",
error.Code, error.Reason);
})
.Build();
consumer.Subscribe(_topic);
try
{
while (!cancellationToken.IsCancellationRequested)
{
try
{
// The Consume call acts as the heartbeat trigger and processes the next record
var consumeResult = consumer.Consume(cancellationToken);
if (consumeResult != null)
{
await ProcessMessageAsync(consumeResult.Message, cancellationToken);
// Store offsets in local memory or commit them periodically/synchronously
consumer.StoreOffset(consumeResult);
// Commit offsets periodically based on batch size or elapsed time
if (consumeResult.Offset.Value % 100 == 0)
{
consumer.Commit(consumeResult);
}
}
}
catch (ConsumeException ex)
{
_logger.LogError(ex, "Error occurred during message consumption: {Reason}", ex.Error.Reason);
}
}
}
catch (OperationCanceledException)
{
_logger.LogInformation("Consumption loop cancellation requested. Shutting down consumer gracefully.");
}
finally
{
// Graceful close guarantees that the coordinator is notified that the static member
// is leaving or shutting down, and commits final offsets.
consumer.Close();
}
}
private async Task ProcessMessageAsync(Message<TKey, TValue> message, CancellationToken cancellationToken)
{
// Business logic implementation
await Task.Delay(10, cancellationToken); // Simulating database write
}
}
}