LSM-Trees vs B-Trees: Storage Engine Internals
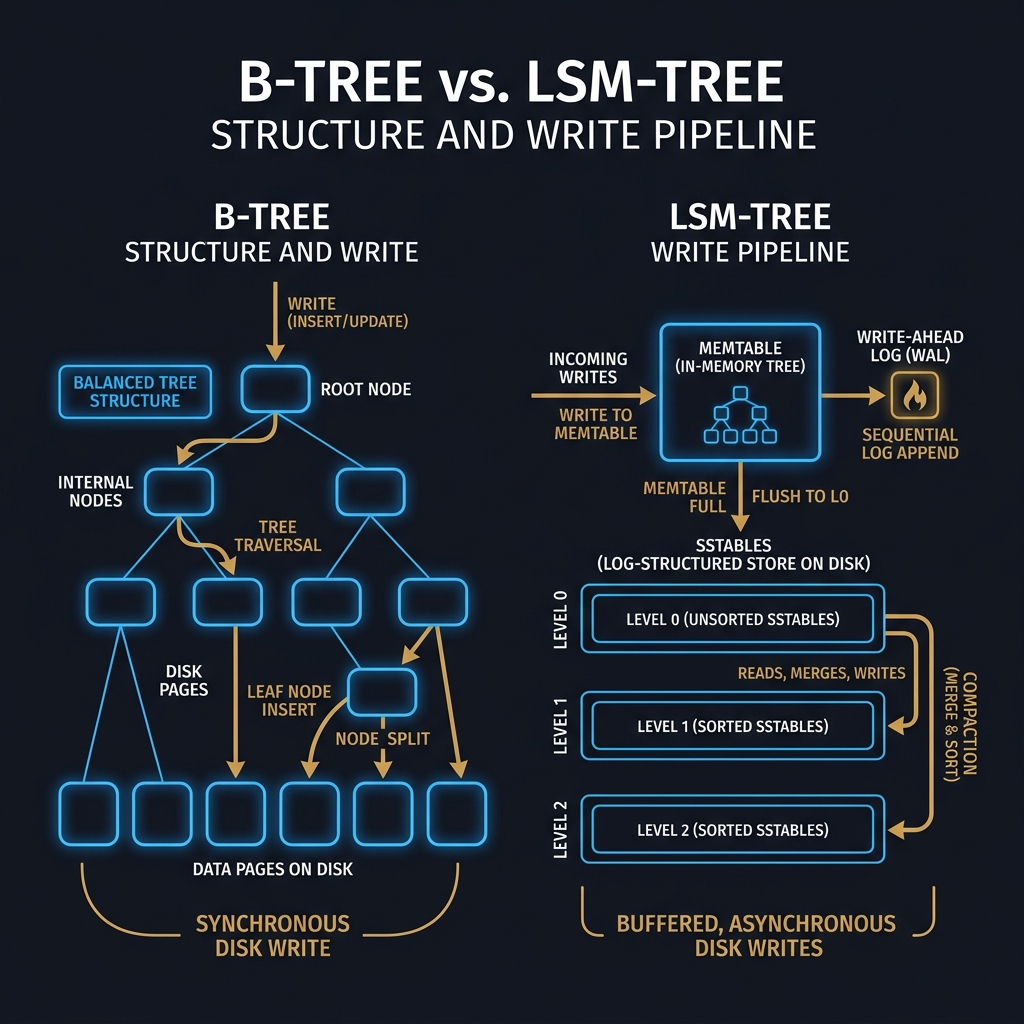
Storage engines lie at the heart of databases. We compare B-Trees (optimized for read-heavy workloads) with Log-Structured Merge-Trees (optimized for write-heavy workloads) from first principles.
Concept
At the bottom of every database sits the storage engine—the subsystem responsible for mapping abstract logical models (tables, documents, graphs) onto physical storage media (NVMe SSDs, persistent memory). Under the hood, storage engine design is dominated by a fundamental physical constraint: the difference in performance between sequential and random I/O. Even with modern NVMe drives, sequential writes are significantly faster and inflict far less write wear than random, in-place overwrites.
Two primary architectural patterns dominate this landscape: page-oriented B-Trees and append-only Log-Structured Merge-Trees (LSM-Trees). They represent two fundamentally opposing design philosophies for managing physical I/O.
B-Trees: In-Place Updates and Page Orientation
Originally designed by Rudolf Bayer and Edward M. McCreight in 1970, the B-Tree (and its ubiquitous variant, the B+ Tree) organizes data into fixed-size blocks called pages (typically 4KB to 16KB, matching the filesystem block size).
The B+ Tree maintains a sorted, self-balancing search tree on disk:
- Internal Nodes contain routing keys and pointers to child pages, guiding traversals.
- Leaf Nodes contain the actual data records or pointers to them, organized in sorted order and linked sequentially (forming a doubly linked list) to optimize range scans.
When a record is updated or inserted:
- The engine traverses the tree from the root to locate the target leaf page.
- The page is loaded into memory (the buffer pool), modified in-place, and marked as "dirty."
- If the insertion exceeds the page capacity, the page is split into two, requiring updates to parent nodes.
- Dirty pages are periodically flushed back to their exact physical location on disk by a background writer thread.
To guarantee durability before flushing dirty pages, B-Trees append a record of the transaction to a sequential Write-Ahead Log (WAL). If a crash occurs, the WAL is replayed to reconstruct the correct state of the pages.
LSM-Trees: Out-of-Place Updates and Sorted Runs
Pioneered by Patrick O'Neil, Edward O'Neil, and Gerhard Weikum in 1996, the LSM-Tree converts random write operations into sequential disk access by deferring updates and sorting them in memory before writing.
An LSM-tree operates as a multi-tiered pipeline:
- MemTable (Memory Table): All incoming writes (inserts, updates, and deletes represented as "tombstones") are written to a sequential Write-Ahead Log (WAL) for durability and simultaneously inserted into an in-memory, sorted data structure (such as a SkipList or Red-Black Tree).
- Immutable MemTable: When the MemTable reaches a size limit (e.g., 64MB), it is marked as immutable, and a new active MemTable is opened.
- SSTables (Sorted String Tables) on Disk: A background thread flushes the immutable MemTable to disk as a Level 0 SSTable. An SSTable is an immutable file containing sorted key-value pairs organized into data blocks, along with an index block mapping keys to offsets.
- Leveled Compaction: Because SSTables are immutable, keys can be duplicated across different files. Over time, background compaction processes merge and de-duplicate SSTables from lower levels (e.g., L0) into higher, larger levels (L1, L2), discarding overridden values and tombstoned records.
graph TD
Write[Client Write] --> WAL[Write-Ahead Log]
Write --> MemTable[Active MemTable - SkipList]
MemTable -- "Threshold Reached" --> ImMemTable[Immutable MemTable]
ImMemTable -- "Sequential Flush" --> L0[SSTable Level 0]
L0 -- "Compaction" --> L1[SSTable Level 1]
L1 -- "Compaction" --> L2[SSTable Level 2]
Constraints
Storage engine performance is governed by the RUM Conjecture, which states that you can optimize for at most two of the following three properties: Read overhead, Update overhead, and Memory/Space overhead.
Write Amplification Factor (WAF)
WAF is the ratio of bytes written to physical storage relative to the logical bytes written by the application: $$\text{WAF} = \frac{\text{Bytes Written to Disk}}{\text{Logical Bytes Written by Application}}$$
- B-Tree WAF: High (often 10–100×). To update a single 100-byte record, the database must write the transaction to the WAL and eventually flush the entire 8KB or 16KB dirty page containing that record back to disk.
- LSM-Tree WAF: Moderately high, but distributed. Writes to the WAL and MemTable flushes are highly sequential (WAF $\approx 1-2$ initially). However, subsequent merge-sorting during compaction means a single byte is read and written multiple times as it migrates up through the levels (accumulated WAF can reach 10–30×).
Read Amplification Factor (RAF)
RAF is the ratio of physical bytes read from storage to the logical bytes requested by the application.
- B-Tree RAF: Low. Locating a key requires traversing $O(\log_B N)$ pages, where $B$ is the branching factor (often $>500$). With the root and top levels cached in memory, a read usually requires only a single disk seek to fetch the target leaf page.
- LSM-Tree RAF: High. A key could reside in the active MemTable, the immutable MemTable, or any of the SSTable levels on disk. In the worst case, the engine must inspect multiple SSTables. LSM-Trees mitigate this using Bloom Filters—probabilistic, memory-efficient data structures associated with each SSTable that check if a key is definitely not present, preventing useless disk reads.
Space Amplification Factor (SAF)
SAF is the ratio of physical disk space utilized to the logical size of the live dataset: $$\text{SAF} = \frac{\text{Disk Space Allocated}}{\text{Logical Size of Live Data}}$$
- B-Tree SAF: Moderate (typically 1.3–2.0×). Internal page fragmentation (e.g., pages that are only 50–70% full due to page splits) accounts for the overhead.
- LSM-Tree SAF: High during peak write workloads (can exceed 2.0×). Space is wasted on duplicate old versions of keys and deleted items (tombstones) waiting for a compaction run to reclaim them.
Trade-offs
The choice between B-Trees and LSM-Trees dictates the performance characteristics of the database under load:
| Metric / Scenario | B-Tree (e.g., InnoDB, PostgreSQL Heap + B-Tree) | LSM-Tree (e.g., RocksDB, Cassandra) |
|---|---|---|
| Write Throughput | Lower. Bound by random page flushes and locking/latching contention in memory. | Extremely High. Writes are buffered in memory and flushed sequentially. |
| Write Latency Tail | Spiky. Page splits and buffer pool flushing checkpoints cause latency spikes. | Smooth, but subject to "compaction write stalls" if disk I/O cannot keep up with writes. |
| Read Latency | Low and predictable. Traversal path is shallow and direct. | Variable. Multiple files may need to be queried, heavily relying on Bloom filters. |
| Range Queries | Very efficient. Leaf nodes are linked; once the start is found, scanning is sequential. | Moderately complex. Requires a multi-way merge-read across multiple SSTables. |
| Hardware Life (SSD) | Low. In-place random overwrites exhaust SSD write endurance quickly. | High. Sequential writes align with SSD wear-leveling algorithms. |
Architectural Decision Tree
Use a B-Tree when:
- Your workload has a read-to-write ratio greater than 10:1.
- Predictable, low-latency point reads are the primary SLA.
- You need strict transaction isolation levels (B-Trees facilitate page-level and key-range locks easily).
Use an LSM-Tree when:
- Write ingestion rate is the primary bottleneck (e.g., time-series data, activity logs).
- Storage footprint optimization is critical (SSTables can be compressed heavily since they are immutable).
- The workload is deployed on cost-effective SSDs where minimizing write endurance wear is desired.
Code
Below is a C# implementation demonstrating the core mechanics of an LSM-Tree write pipeline: buffering writes to an active memory table, appending to a Write-Ahead Log (WAL), flushing to a simulated sorted SSTable file on disk, and performing binary search lookups using a sparse block index.
using System;
using System.Collections.Concurrent;
using System.Collections.Generic;
using System.IO;
using System.Text;
using System.Threading;
using System.Threading.Tasks;
namespace StorageEngineInternals
{
public record DataRecord(string Key, byte[] Value, long Timestamp, bool IsTombstone = false);
public class LsmStorageEngine : IDisposable
{
private readonly string _dbPath;
private readonly string _walPath;
private readonly int _memtableThresholdBytes;
private readonly ReaderWriterLockSlim _rwLock = new();
private SortedDictionary<string, DataRecord> _memTable = new(StringComparer.Ordinal);
private FileStream _walStream;
private int _currentMemTableSizeBytes = 0;
private int _sstableCounter = 0;
public LsmStorageEngine(string dbPath, int memtableThresholdBytes = 1024 * 1024)
{
_dbPath = dbPath;
_memtableThresholdBytes = memtableThresholdBytes;
Directory.CreateDirectory(_dbPath);
_walPath = Path.Combine(_dbPath, "commit.wal");
_walStream = new FileStream(_walPath, FileMode.OpenOrCreate, FileAccess.Write, FileShare.Read, 4096, FileOptions.WriteThrough);
RecoverFromWal();
}
public void Put(string key, byte[] value) => WriteInternal(new DataRecord(key, value, DateTime.UtcNow.Ticks));
public void Delete(string key) => WriteInternal(new DataRecord(key, Array.Empty<byte>(), DateTime.UtcNow.Ticks, IsTombstone: true));
private void WriteInternal(DataRecord record)
{
_rwLock.EnterWriteLock();
try
{
// 1. Append to WAL (Write-Ahead Log)
AppendToWal(record);
// 2. Insert into MemTable
_memTable[record.Key] = record;
_currentMemTableSizeBytes += record.Key.Length + record.Value.Length + sizeof(long) + 1;
// 3. Flush if threshold exceeded
if (_currentMemTableSizeBytes >= _memtableThresholdBytes)
{
FlushMemTable();
}
}
finally
{
_rwLock.ExitWriteLock();
}
}
public byte[]? Get(string key)
{
_rwLock.EnterReadLock();
try
{
// 1. Search MemTable
if (_memTable.TryGetValue(key, out var record))
{
return record.IsTombstone ? null : record.Value;
}
}
finally
{
_rwLock.ExitReadLock();
}
// 2. Search SSTables on disk (newest first)
for (int i = _sstableCounter - 1; i >= 0; i--)
{
var sstablePath = Path.Combine(_dbPath, $"sst_{i}.db");
if (File.Exists(sstablePath))
{
var record = SearchSstable(sstablePath, key);
if (record != null)
{
return record.IsTombstone ? null : record.Value;
}
}
}
return null;
}
private void AppendToWal(DataRecord record)
{
var keyBytes = Encoding.UTF8.GetBytes(record.Key);
_walStream.WriteByte((byte)(record.IsTombstone ? 1 : 0));
_walStream.Write(BitConverter.GetBytes(record.Timestamp));
_walStream.Write(BitConverter.GetBytes(keyBytes.Length));
_walStream.Write(keyBytes);
_walStream.Write(BitConverter.GetBytes(record.Value.Length));
_walStream.Write(record.Value);
_walStream.Flush();
}
private void FlushMemTable()
{
if (_memTable.Count == 0) return;
var sstablePath = Path.Combine(_dbPath, $"sst_{_sstableCounter++}.db");
using (var fs = new FileStream(sstablePath, FileMode.Create, FileAccess.Write))
using (var writer = new BinaryWriter(fs))
{
// Write sparse index format: Key -> Offset
var index = new List<(string Key, long Offset)>();
foreach (var record in _memTable.Values)
{
index.Add((record.Key, fs.Position));
writer.Write(record.IsTombstone);
writer.Write(record.Timestamp);
writer.Write(record.Key);
writer.Write(record.Value.Length);
writer.Write(record.Value);
}
// Write Index boundary pointer
long indexStartOffset = fs.Position;
writer.Write(index.Count);
foreach (var indexEntry in index)
{
writer.Write(indexEntry.Key);
writer.Write(indexEntry.Offset);
}
writer.Write(indexStartOffset); // Footer: points to start of index block
}
// Clear WAL and MemTable
_walStream.Dispose();
File.Delete(_walPath);
_walStream = new FileStream(_walPath, FileMode.Create, FileAccess.Write, FileShare.Read, 4096, FileOptions.WriteThrough);
_memTable.Clear();
_currentMemTableSizeBytes = 0;
}
private DataRecord? SearchSstable(string path, string key)
{
using var fs = new FileStream(path, FileMode.Open, FileAccess.Read);
using var reader = new BinaryReader(fs);
// Read index offset from footer (last 8 bytes)
fs.Seek(-8, SeekOrigin.End);
long indexStartOffset = reader.ReadInt64();
// Load sparse index
fs.Seek(indexStartOffset, SeekOrigin.Begin);
int indexCount = reader.ReadInt32();
var index = new List<(string Key, long Offset)>(indexCount);
for (int i = 0; i < indexCount; i++)
{
var idxKey = reader.ReadString();
var idxOffset = reader.ReadInt64();
index.Add((idxKey, idxOffset));
}
// Binary search within the loaded sparse index
int low = 0;
int high = index.Count - 1;
int targetIdx = -1;
while (low <= high)
{
int mid = low + (high - low) / 2;
int compare = string.Compare(index[mid].Key, key, StringComparison.Ordinal);
if (compare == 0)
{
targetIdx = mid;
break;
}
if (compare < 0)
{
targetIdx = mid; // Closest index element smaller than target
low = mid + 1;
}
else
{
high = mid - 1;
}
}
if (targetIdx == -1) return null;
// Seek to offset found in binary search
fs.Seek(index[targetIdx].Offset, SeekOrigin.Begin);
while (fs.Position < indexStartOffset)
{
bool isTombstone = reader.ReadBoolean();
long timestamp = reader.ReadInt64();
string recKey = reader.ReadString();
int valLen = reader.ReadInt32();
byte[] val = reader.ReadBytes(valLen);
int compare = string.Compare(recKey, key, StringComparison.Ordinal);
if (compare == 0)
{
return new DataRecord(recKey, val, timestamp, isTombstone);
}
if (compare > 0)
{
break; // Passed target key, does not exist in this SSTable
}
}
return null;
}
private void RecoverFromWal()
{
if (!File.Exists(_walPath)) return;
using var readFs = new FileStream(_walPath, FileMode.Open, FileAccess.Read, FileShare.ReadWrite);
if (readFs.Length == 0) return;
using var reader = new BinaryReader(readFs);
try
{
while (readFs.Position < readFs.Length)
{
bool isTombstone = reader.ReadByte() == 1;
long timestamp = reader.ReadInt64();
int keyLen = reader.ReadInt32();
string key = Encoding.UTF8.GetString(reader.ReadBytes(keyLen));
int valLen = reader.ReadInt32();
byte[] value = reader.ReadBytes(valLen);
var record = new DataRecord(key, value, timestamp, isTombstone);
_memTable[key] = record;
}
}
catch (EndOfStreamException)
{
// Handle partial WAL record write
}
}
public void Dispose()
{
_rwLock.EnterWriteLock();
try
{
FlushMemTable();
_walStream.Dispose();
_rwLock.Dispose();
}
finally
{
_rwLock.ExitWriteLock();
}
}
}
}